The ``prior probability'' ![]() represents the chance that the image b
represents the true map before any data is taken into account. This ``prior
probability'' is a measure of how simple an image is, since simple images are
more probable (a priori) than complex images.
represents the chance that the image b
represents the true map before any data is taken into account. This ``prior
probability'' is a measure of how simple an image is, since simple images are
more probable (a priori) than complex images.
The Prior Probability
How do we get the "prior probability" ![]() ?
A monkey argument was suggested by Gull and Daniell (1978).
?
A monkey argument was suggested by Gull and Daniell (1978).
Suppose a monkey tosses N identical photons into M identical pixels: (The
order of the pixels in image
![]() is regarded as
irrelevant, and the photons are identical.
is regarded as
irrelevant, and the photons are identical.
Number of photons in jth pixel = ![]()
Number of ways to get a given image
![]()
| (1) |
The a priori probability of getting a given image b is therefore
this number divided by the number of all possible maps:
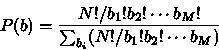 |
(2) |
If there are many photons in each pixel (![]() ) we can use
Stirling's approximation for the factorial,
) we can use
Stirling's approximation for the factorial,
![]() .
Using this,
.
Using this,
![]() .
.
It is much more convenient to normalize all the pixel intensities ![]() to the so-called ``grey map'', where all the intensities equal the
mean value
to the so-called ``grey map'', where all the intensities equal the
mean value ![]() .
.
| (3) |
where ![]() is a normalizing constant that guarantees that
is a normalizing constant that guarantees that ![]() sums to 1
over all possible maps
sums to 1
over all possible maps ![]() .
. ![]() is the probability of the ``grey'' map,
since all the factors
is the probability of the ``grey'' map,
since all the factors ![]() in equation (3) are 1 in that case. It can be shown that
in equation (3) are 1 in that case. It can be shown that
![]() is the maximum value of
is the maximum value of ![]() .
.
None of this looks at all like the ``entropy'' term we are familiar with in
MEM, but equation (3) can be re-written in an exponential form which gives us the
so-called ``entropy'' term
![]() .
.
| (4) |
In our derivation, ![]()
The Likelihood
Now that we have the ``prior'' probability, we need to find the "likelihood".
The "likelihood" ![]() (``P of D given b'') is the probability that the
observed data D could have been generated from a given image b. )
(``P of D given b'') is the probability that the
observed data D could have been generated from a given image b. )
This probability is computed using the difference of the simulated data
![]() computed from some guess for the image b and the real data D. For
Gaussian statistics,
computed from some guess for the image b and the real data D. For
Gaussian statistics,
| (5) |
In somewhat more generality,
| (6) |
This is true for a sufficiently large number of photons that ![]() is a valid measure of departures from data. If the number of photons
is small, one must use something like the C-statistic (Cash, 1978).
is a valid measure of departures from data. If the number of photons
is small, one must use something like the C-statistic (Cash, 1978).
But what we want for the deconvolution is not ![]() but
but ![]() ,
that is, the probability of the image b given the data D. This is given
by Bayse's theorem:
,
that is, the probability of the image b given the data D. This is given
by Bayse's theorem:
| (7) |
P(b) is the prior probability of image b, ![]() is the likelihood
of the data given b, and P(D) is a constant which normalizes
is the likelihood
of the data given b, and P(D) is a constant which normalizes ![]() to a sum of unity, and gives the probability of the data.
to a sum of unity, and gives the probability of the data.
At last we can write down the quantity to be maximized. Inserting the
expressions (2) and (4) for ![]() and
and ![]() into equation (5), we get:
into equation (5), we get:
| (8) |
where C is a normalizing constant that guarantees that the sum of the
probabilities is 1.
All we need to do now is find the image b that maximizes ![]() ),
which is the same as maximizing
),
which is the same as maximizing ![]() :
:
| (9) |
The first term is the constraint of the data; it is 0 when the image matches the
data perfectly, but in realistic cases is ![]() when
the data are fitted but not ``over fitted''. The second term
is commonly called the "entropy" term, which guarantees the "simplicity"
of the image. (It is not really the entropy in the sense used by Shannon (1948),
but the weight of common use forces us to call it that.) The ``entropy''
term is maximum (0) when
when
the data are fitted but not ``over fitted''. The second term
is commonly called the "entropy" term, which guarantees the "simplicity"
of the image. (It is not really the entropy in the sense used by Shannon (1948),
but the weight of common use forces us to call it that.) The ``entropy''
term is maximum (0) when ![]() . That is, the ``grey'' map is a priori
most probable.
. That is, the ``grey'' map is a priori
most probable.
Note the arbitrary coefficient ![]() giving relative weight to the
``entropy'' term. If
giving relative weight to the
``entropy'' term. If ![]() , Bayesian logic would give equal weight to
each term, but MEM algorithms usually weight them differently to provide simpler maps (
, Bayesian logic would give equal weight to
each term, but MEM algorithms usually weight them differently to provide simpler maps (![]() )
or maps more faithful to the data (
)
or maps more faithful to the data (![]() ). It is possible, using
Bayseian arguments, to estimate the most probable
). It is possible, using
Bayseian arguments, to estimate the most probable ![]() (Skilling 1989)
(Skilling 1989)
Since the dimensionality of the parameter space for MEM is the number of map
pixels, we cannot show contours of the function ![]() ) in a realistic
case. Instead we show a case for 3 pixels, {
) in a realistic
case. Instead we show a case for 3 pixels, {![]() }, where the sum
of the pixel brightnesses equals 100. This reduces it to a 2-dimensional
problem. In the figure below, the dashed contours represent the entropy
function
}, where the sum
of the pixel brightnesses equals 100. This reduces it to a 2-dimensional
problem. In the figure below, the dashed contours represent the entropy
function ![]() , and the solid contours show the
, and the solid contours show the ![]() function. The
squares are located at the maximum of
function. The
squares are located at the maximum of ![]() for different values of
for different values of
![]() . When
. When ![]() , the maximum is located at the entropy peak,
and when
, the maximum is located at the entropy peak,
and when ![]() , it is located at the minimum of
, it is located at the minimum of ![]() .
.
![]()
This figure shows a cross-section through the (3-D) likelihood
hypercube. In general, the likelihood
hypercube will have a number of dimensions equal to the number of
map pixels (e.g. 4096 for a 64x64 map).
This 3-pixel example is more general than one might at first think. In fact,
for an arbitrary number of pixels, any two-dimensional cross section
of the N-dimensional entropy function through parameter space will look
much like this. The cross-sections of the ![]() function will always be
ellipses with, of course, different centroids and axial ratios.
function will always be
ellipses with, of course, different centroids and axial ratios.
There is a special high-noise case in which the ![]() = 1
surface is outside the entropy=0 point. This happens when the sigmas
are larger than the distance from the entropy=0 point to the
= 1
surface is outside the entropy=0 point. This happens when the sigmas
are larger than the distance from the entropy=0 point to the ![]() = 0
point. For example:
= 0
point. For example:
![]()
In this case, the track given by alpha=infinity to zero does not cross
the surface ![]() = 1 at the point of maximum entropy (marked by the
"bulls eye".)
This may never happen with RHESSI data, but it is worth investigating.
= 1 at the point of maximum entropy (marked by the
"bulls eye".)
This may never happen with RHESSI data, but it is worth investigating.
The goal of MEM is to find the optimum
value along this curve, somewhere in parameter space between the "prior" grey
map and the map which fits the data exactly. Skilling has argued that the
``most probable'' ![]() is the one that makes the number of ``good'' measurements
equal to -
is the one that makes the number of ``good'' measurements
equal to -![]() , which is the (dimensionless) amount of structure in
the map
, which is the (dimensionless) amount of structure in
the map ![]() . The number of ``good'' measurements is defined by a sum over curvature
terms in the likelihood matrix (Skilling 1989).
. The number of ``good'' measurements is defined by a sum over curvature
terms in the likelihood matrix (Skilling 1989).