Object-Oriented
Data Analysis Software Concept
This document describes object-oriented concepts used to
implement scientific data analysis tasks, mainly in the context of the HESSI
data analysis software. It also describes the method to implement custom data
analysis tasks using frameworks and strategy holders. This description assumes
an IDL
solarsoft
environment.
Introduction. 1
Object
instance creation. 2
Primary
data access. 2
Abstract
classes and concrete classes. 3
How
to use a framework. 4
Strategies
and Strategy Holders. 8
How
to work wih strategy holders. 9
The HESSI data analysis
software uses object classes to stepwise reconstruct images, spectra and light
curves from raw data. Each step of the construction is associated with an object
class. An object class is defined as
en entity describing a data type and the methods (i.e., procedures and functions) to access and handle it. In
the context discussed here, an object class includes a primary data type, a
process method, control and information parameters, accessor methods and display methods.
- The primary data type defines the
structure of the data managed by a given object class implementation.
- The process method implements or
calls the algorithm that transforms a given input (source) data into the
primary data type managed by the class.
- Control and information parameters pass values between the algorithm
implemented in the process method and the object client (i.e. the user of
the object, which can be either a person or another object). Control
parameters are used to control the behavior of the algorithm. Information
parameters are used to pass metadata information about the primary data
generated by the algorithm.
- Accessor methods retrieve subsets of the primary data
requested by the client object or user. They also retrieve control or
information parameter values, and allow setting control parameter values.
- Display
methods allow users to output to a specific media (screen, printer,
image files) both primary data or parameters.
An instance of an object
class must be first created before it can be used. Here is the idl command to
do this:
IDL> o = Obj_New( 'class_name' )
An IDL object reference
variable o
is returned by the instance creation function. Data and methods associated with
the object can be accessed with this variable. In the instance creation
function, default values are set (i.e. assigned) to control parameters. Often,
a constructor function is used to create the object reference:
Primary data requests
are handled by the accessor method GetData:
o is the object reference created
by the instance creation function (1). The object first checks whether its
state is consistent, that is, if the primary data contained in the object
corresponds to the values of the control parameters. If the object state is
consistent, GetData returns (i.e. passes to the client that issued the request) the
data that is contained in the internal memory area of the object. If the object
state is not consistent, the GetData method calls first the Process method, which puts the object
back into a consistent state by running the transformation procedure associated
with the class. After the transformation procedure has completed, the data is
returned to the client.
Although the Process method can be defined fully
arbitrarily, it usually includes four steps.
- The control parameters associated with
the specific object (and thus associated with the algorithm) are loaded.
- Data are read from a given source,
usually (but not necessarily) by requesting data from another object, its source,
of the same parent abstract class (abstract classes will be discussed
below).
- The algorithm runs for the specific
control parameters and source data. It generates the primary data.
- The primary data and the (optional)
informational parameters are stored into the object's memory area.
Object classes can be
divided into abstract and concrete classes.
- Abstract classes define generic operations (most
importantly accessor methods) that can be used, or implemented, by
concrete object classes. Abstract classes are also called parent
classes.
- Concrete classes implement an abstract class, i.e. they
inherit an abstract class and define the data types and algorithms to use
with this specific implementation of the abstract class. Concrete classes
are also called child classes.
Abstract classes are
never used alone. Their existence (as good parents!) makes sense only through
concrete classes (their child).
For HESSI, concrete
classes are divided into several groups.
- Utility classes are “low-level” objects, and the
largest group of objects. They allow reading data from files, simulating
data, and generating intermediate and diagnostic data products used by
higher-level objects. Most important utility classes are HSI_Packet, HSI_Eventlist, HSI_Calib_Eventlist, HSI_Modul_Pattern, HSI_Modul_Profile.
- Imaging classes are "high-level" objects, and
the second largest group of objects. They define the imaging algorithms
and the data products related to imaging tasks. Most important are HSI_BProj, HSI__PSF, HSI_Image, HSI_Clean, HSI_MEM_Sato, HSI_Pixon, HSI_Forwardfit.
- Spectroscopy classes define the data structures and
algorithms used for spectroscopy tasks. Most important are HSI_Spectrum, HSI_Spectrogram.
- Lightcurve classes define the data structures and
algorithms used for time series applications. Most important are HSI_Lightcurve and HSI_Binned_Eventlist.
All HESSI classes
have a common parent class. This common parent class is called Framework.
It contains the code of the generic methods Get, GetData, Set, SetData, Plot, Write, Print. Because all classes inherit Framework,
they implement the same interface. In other words, the same accessor and
display methods are available for each class. As a result, and because each
processing step reads data from a source object which implements the same
parent class (a sibling object), the software actually reuses at all
levels the same code of a single accessor method. A graphical representation of
the framework is given in Figure 1.
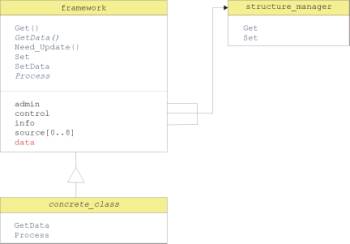
Figure 1: The framework defines the basic methods required for
data analysis tasks. It defers the implementation of the data-type dependent
operations (e.g., Process) to the concrete class that inherits the framework.
The process of analyzing
data consists of a chain of transformation processed by sibling objects. A
given class gets data from a source class, and passes data to a client class.
The last client, of course, is the user.
Classes can be organized
in well-defined design patterns. For HESSI, the imaging algorithms implement
the template method pattern. An abstract class hsi_image_alg is common to all
imaging algorithms. A (small) concrete class implements a so-called hook
that contains the actual image algorithm (clean, mem, pixon, forward fit). All
other processing steps are common and therefore implemented in the abstract
class. In this way, the client object does not need to care what it uses for
imaging algorithm. It only knows that it has for source an object with parent
class of type hsi_image_alg
This describes how you
can use a framework for your own data analysis tasks. Let us assume that you
have implemented an algorithm and you want to manage it using a framework.
First, why do you want that? There are several reasons.
- The Framework gives you
a way of implementing a standard access interface consistent with the
interface of other algorithms managed by a framework;
- The Framework gives you
a way of keeping already generated data products in memory,
avoiding excessive recalculations;
- The Framework provides
you with a mechanism to check whether a data product is already
available or whether it needs to be calculated
- The Framework provides
you with a way of setting up a whole set of collaborations between
independent classes.
- The Framework spares
you development time of code that has already been developed
Let's assume you have
implemented an algorithm algo, and you want
to manage it with a framework. algo has the following declaration (or interface):
PRO Algo, input, output, param1, param2, out_param1, out_param2,
KEYWORD1=keyword1, KEYWORD2=keyword2
input is a variable containing the
data to be processed by the algorithm (source data), output is the data generated by the
algorithm, param1 and param2 are input (control) parameters, and out_param1 and out_param2 are output (info) parameters.
Last, keyword1 and keyword2 are keyword values that can be set by users at run time.
There are a number of
IDL templates ready to help you in the implementation. You can find these
templates in your SSW installation in the directory $SSW/hessi/idl/objects, or you can get them here:
framework_template__define.pro framework_template_control__define.pro,
framework_template_control.pro,
framework_template_info__define.pro.
Here is how you deal
with it:
- Configure the
control parameter structure. all control parameters should be declared in a structure, e.g.
with name algo_control__define.pro. You can use framework_template_control__define.pro
to help you. The control structure {algo_control} would look like this:
PRO
Algo_Control__Define
struct =
{algo_control, param1: 0L, param2: 0.}
END
(the type of the parameters is arbitrary)
- Configure the
control parameter initialization function. In this function, you will assign to
the variables the default values you want to provide. The function may
have the same name as the control structure without the __define at the end, e.g. algo_control.pro. You can use framework_template_control.pro
to help you. The initialization function for algo_control would look like this:
FUNCTION Algo_Control
var = {algo_control}
var.param1 = 1002L
var.param2 = !pi
RETURN, var
END
- Configure the
information parameter structure. All information parameters should be declared in a structure,
e.g. with name algo_info__define.pro. You can use framework_template_info__define.pro to help you. The information structure {algo_info} would look like this:
PRO
Algo_Info__Define
struct = {algo_info,
out_param1: 0B, out_param2: 0D}
END
(the type of the parameters is arbitrary)
- Now you will need to
make a copy of framework_template__define.pro to
whatever your future class should be named, e.g. algo__define.pro Replace all occurrences of framework_template with algo.
- Configure the INIT procedure In INIT, you will pass the control and information structures defined in
steps above to the framework so that it knows what to manage. Furthermore,
you can pass the source object that will be used by the process method to
read data from another framework-type of class, if available. Note: inside
of an object, methods and parameters are accessed using the self-reference
of the object called self.
For instance the init procedure for algo will look like this:
FUNCTION
Algo::INIT, SOURCE = source, _EXTRA=_extra
IF NOT Obj_Valid( source ) THEN BEGIN
source = obj_new(
'algo_source' )
ENDIF
ret=self->Framework::INIT( CONTROL=framework_template_control(),$
INFO={framework_template_info}, $
SOURCE=source,
$
_EXTRA=_extra )
RETURN, ret
END
- Configure the Process procedure. According to the description above,
process needs to read in the control parameters, call the function or
procedure implementing the algorithm, passing any parameters and/or
keywords requested by the algorithm, store the result of the
transformation into the object memory, and store information parameters
into the information structure. For instance, the Process for algo would look like this:
PRO
Algo::Process, KEYWORD1=keyword1, KEYWORD2=keyword2
param1 = self->Get( /PARAM1 )
param2 = self->Get( /PARAM2 )
source = self->Get( /SOURCE )
data = source->GetData( _EXTRA = _extra )
Algo, input, output, param1, param2, $
out_param1, out_param2, $
KEYWORD1=keyword1, KEYWORD2=keyword2
self->SetData, output
self->Set, OUT_PARAM1 = out_param1
self->Set, OUT_PARAM2 = out_param2
END
`
- Configure the
GetData function. This
step is optional. If your algorithm outputs a complex data structure, it
may be a good idea to provide some keywords to access subsets of the data,
without involving a call to the Process method. Extending the functionality of the default GetData method
can do this. Lets assume the output of Algo is a 3D array, and you want to access slices of this
"cube". You would define a set of keywords that would allow
selecting the slices, putting a THIS_ string in front of
the keyword name to distinguish the accessor keywords from the control
parameters. Thus the GetData method would look like this
FUNCTION Algo::GetData, $
THIS_X_SLICE=this_x_slice, $
THIS_Y_SLICE=this_y_slice, $
THIS_Z_SLICE=this_z_slice, _EXTRA=_extra
data=self->Framework::GetData( _EXTRA = _extra )
; actually this could be done more nicely, but anyway...
IF Keyword_Set( THIS_X_SLICE ) THEN BEGIN
RETURN,
data[this_x_slice,*,*]
ENDIF ELSE IF Keyword_Set( THIS_Y_SLICE ) THEN BEGIN
RETURN,
data[*,this_y_slice,*]
ENDIF ELSE IF Keyword_Set( THIS_Z_SLICE ) THEN BEGIN
RETURN, data[*, *, this_z_slice
]
ENDIF
RETURN, data
END
- Configure the Set
procedure.This step is
optional. It is sometimes necessary to do some specific action when a
parameter is set, for instance when two parameters are dependent from each
other. In this case the extended function woudl look like this:
PRO Algo::Set,
$
PARAMETER=parameter,
$
_EXTRA=_extra
IF Keyword_Set( PARAMETER ) THEN BEGIN
; first set the parameter using the original Set
self->Framework::Set, PARAMETER = parameter
; then take some action that depends on this parameter
Take_Some_Action,
parameter
ENDIF
; for all other parameters (included in _extra), just pass them to the
; original Set procedure in Framework
IF Keyword_Set( _EXTRA ) THEN BEGIN
self->Framework::Set, _EXTRA = _extra
ENDIF
END
Configure the Get function. This step is optional.
The Get function needs to be modified only in very special cases, e.g. if you
need to modify the value before passing in back to the user. This is not
recommended, however. Note that two keyword variables NOT_FOUND
and FOUND
must be passed to the Get function in Framework. Note also that you eventually
need to retrieve parameter from the original Get function, otherwise
most of the functionality of the Get function will not work (e.g. aggregation
of requested parameters in a structure).
FUNCTION Algo::Get, $
NOT_FOUND=NOT_found,
$
FOUND=found, $
PARAMETER=parameter,
$
_EXTRA=_extra
IF Keyword_Set( PARAMETER ) THEN BEGIN
parameter_local =
self->Framework::Get( /PARAMETER )
Do_Something_With_Parameter, parameter_local
ENDIF
RETURN, self->Framework::Get( PARAMETER=parameter, $
NOT_FOUND = not_found, $
FOUND=found, _EXTRA = _extra )
END
In many occasions, we need more
functionality than what is given by the framework. The framework is limited to
the management of one single data type in a single class. So what happens if we
have to deal with several related data types or classes? One general extension
of the framework can be the grouping of a number of related classes into
a single class. From this single class, each specific class can be accessed in
an integrated way. The classes belonging to the group are called strategies
to denote that they are aiming at a related goal, but use different strategies
to reach this goal. The single class that allows access to the individual
strategies is called strategy holder.
In the context of HESSI, a good illustration of the grouping
into strategy objects is given by the class hsi_image.
This class is a child of the strategy holder class. It holds several
strategies, used to “clean” a “dirty” image. Strategies include the clean
algorithm, forward fitting, pixon, and maximum entropy. From hsi_image, users (or clients in
general) can specify each strategy by specifying the name of the associated
class. They can switch from one algorithm to the other, e.g. from the
"clean" algorithm to the "forward fit" algorithm just by
giving the new name. If they want to access data from another strategy, they
have only to change the strategy name:
O = hsi_image()
im_clean = o->getdata( image_algorithm = ‘clean’ )
im_fwd = o->getdata( image_algorithm = ‘forward fit’ )
The collaboration between
strategies and strategy holder can be compared to the “case” statement for
programming languages: the case statement corresponds to the strategy holder,
the statements withing the case block correspond to the strategies.
The use of strategies has several
advantages:
-
Reusability. The pattern implemented by the collaboration between
strategies and strategy holders happens frequently. Therefore, the mechanism
isolated into the strategy holder can be reused at many different places
-
Integration. Switching between different strategies is standard, that
is, its use is straightforward for the clients. Furthermore, control and
information parameters associated with a single strategy can be accessed even
when the strategy is not used.
-
Efficiency. The strategy classes that have already an instance are kept
accessible until the strategy holder is destroyed. This allows keeping around
objects ready for further use, when a client needs them at a later time.
The strategy holder pattern involves several collaborating
classes. In the design pattern world, classes that share a common behavior are
called strategies. Those that contain multiple implementation of a same base
abstract class are called flyweight. Therefore, the strategy holder pattern is
a kind of mixture between both. of these standard patterns. It is illustrated
in Figure 2.
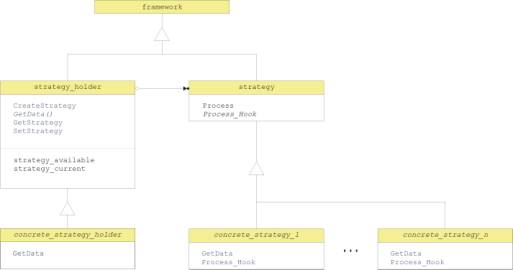
Figure 2: The strategy holder pattern
One main characteristics of the
strategy holder is that it holds not only the object references to the
strategies, but also the (common) source object that is shared by the
strategies.
The way strategy holders work is
as follows. At initialization, the strategy holder gets a list of the
strategies it needs to hold. During the existence of the strategy holder, the
data in the strategies can be accessed indifferently. Also, the strategy holder
usually
Let's assume you have defined a
number of related classes: besides algo__define you have algo_1__define
and algo_2__define.
These three algorithm share some common code that you want to reuse, in a class
called algo_strategy__define,
thus they should all
inherit this abstract class. You want to manage these three related algorithms
with a strategy_holder, and the three algorithms will be made accessible
through the interface called algo_together__define.
- Configure
the common strategy class.
This can be done by looking at the three classes and finding out which
code is the same for all. Then create the class algo_strategy__define, which inherits the framework, and will have all the normal
procedures extending the framework. The process procedure, however, will look a bit different.
It will contain the call to the procedure process_hook, which will be
defined in the next step, in the cioncrete class. Thus, it will look like
this:
PRO
Algo_Strategy_Define::Process, EXTRA =extra
parameters_in =
self->Get( /CONTROL, /THIS_CLASS_ONLY )
; .. do the common things
here
self->Process_hook,
parameters_in, parameters_out, data, $
_EXTRA = _extra
; .. do more common things here
self->Set, INFO =
parameters_out
self->SetData, data
END
- Configure the concrete strategy classes.
These classes will
inherit the common strategy class, and they will mainly define the
algorithm-dependent procedure process_hook. Of course you can also redefine Set, Get, or GetData at
any level. The hook will look about like this (please compare this to the
procedure in the discussion of the framework configuration):
PRO
Algo::Process_Hook, param_in, param_out,
_EXTRA = _extra
param1 = param_in.param1
param2 = param_in.param2
source = self->Get(
/SOURCE )
data = source->GetData(
_EXTRA = _extra )
Algo, input, output,
param1, param2, $
out_param1,
out_param2, $
KEYWORD1=keyword1,
KEYWORD2=keyword2
param_out = {out_param1:
out_param1, out_param2: out_param2}
END
- Configure
the strategy holder. In the initialization procedure, you must declare
which strategies will be managed by the strategy holder. These are the
classes configured in the steps above. Usually, you have to declare their
names in the initialization procedure, which will look like this:
FUNCTION Algo_together::INIT
strategies_available = [‘ALGO’,’ALGO_1’,’ALGO2’]
self->Strategy_Holder::INIT( strategies_available )
END
Note that the configuration of the strategy class
collaboration is more complex than the configuration of the framework.
Therefore, the description given above does not grasp all the implementation
details, but rather tries to give a feeling on how to deal with this kind of
implementation.